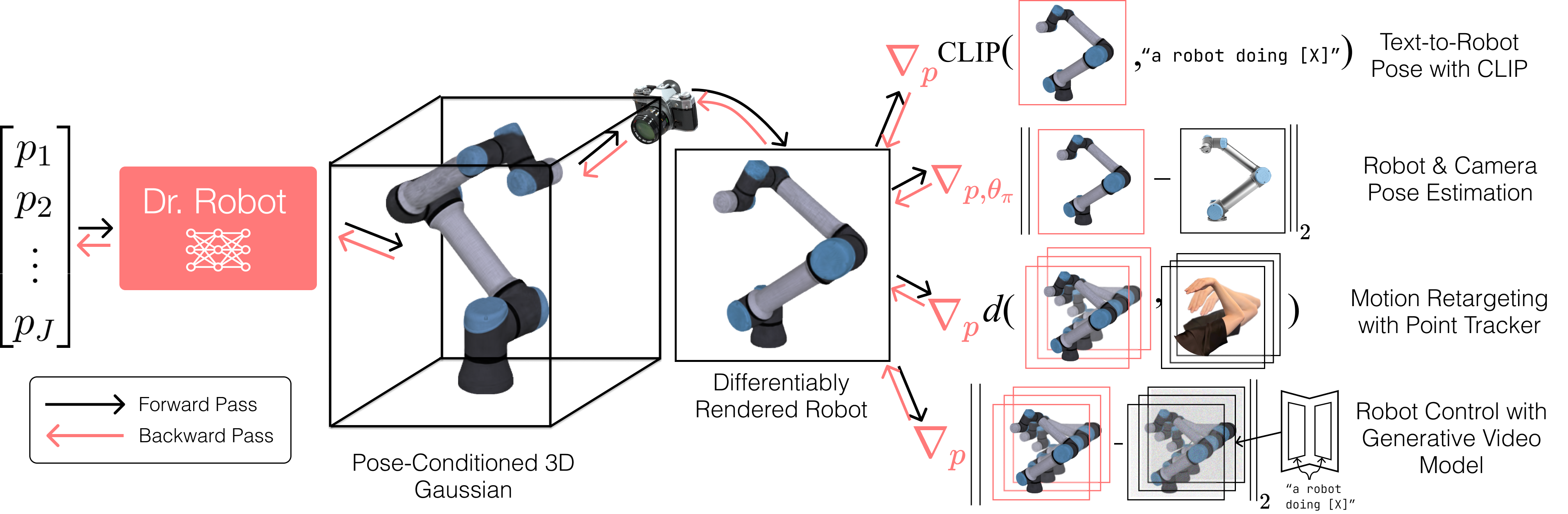
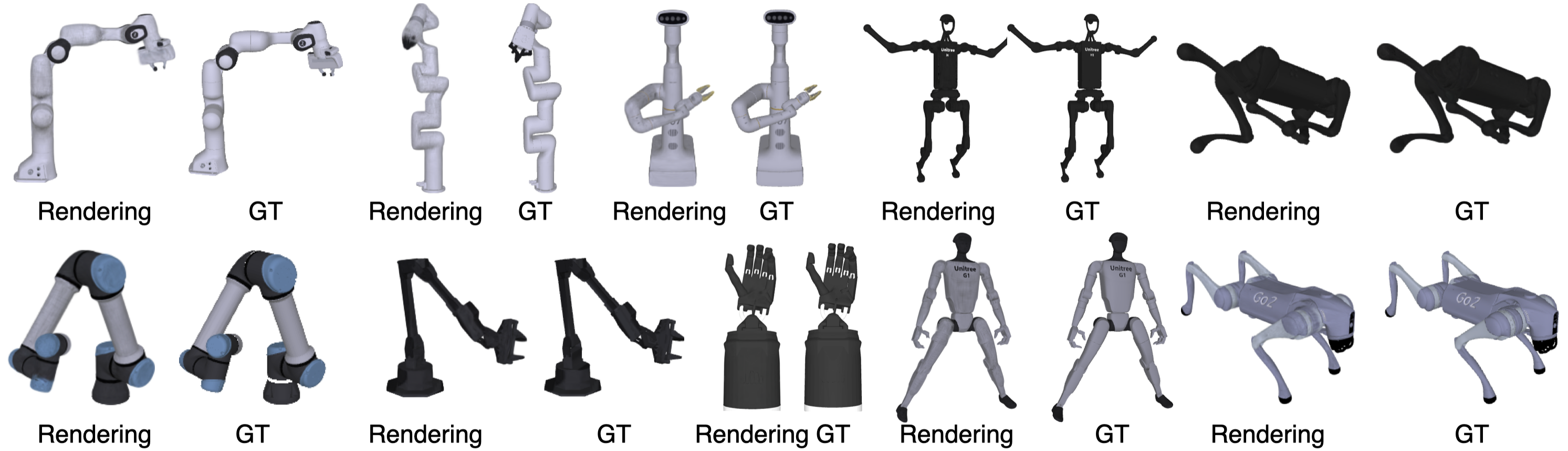
Vision foundation models trained on massive amounts of visual data have shown unprecedented reasoning and planning skills in open-world settings. A key challenge in applying them to robotic tasks is the modality gap between visual data and action data. We introduce differentiable robot rendering, a method allowing the visual appearance of a robot body to be directly differentiable with respect to its control parameters. Our model integrates a kinematics-aware deformable model and Gaussians Splatting and is compatible with any robot form factors and degrees of freedom. We demonstrate its capability and usage in applications including reconstruction of robot poses from images and controlling robots through vision language models. Quantitative and qualitative results show that our differentiable rendering model provides effective gradients for robotic control directly from pixels, setting the foundation for the future applications of vision foundation models in robotics.

@misc{liu2024differentiablerobotrendering,
title={Differentiable Robot Rendering},
author={Ruoshi Liu and Alper Canberk and Shuran Song and Carl Vondrick},
year={2024},
eprint={2410.13851},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2410.13851},
}